Multiple engineers, each with their own coding agent, one shared codebase. How do you avoid chaos?
Your team already knows how to coordinate on code. Git, feature branches, pull requests. This is considered best practice and all software teams that I know are working with this.
Agentic engineering doesn’t change this model. What it changes is what needs to travel alongside the code:
- Intent must be formalized and shared. Coding agents need structured context to make good decisions. That context has to be part of the shared codebase in the repository.
- Implementation gets faster, so coordination must keep up. When features ship in hours instead of weeks, the feedback loop between parallel efforts tightens.
Git coordinates code. But code only captures what was built. It doesn’t capture what was intended, what was decided against, or what constraints other features depend on. When Tim merges a restructured billing module on Monday and Hannah starts building on that module on Tuesday, her agent has no idea why Tim changed the interface, what constraints he introduced, or what behavior he expects. The code is there, but the reasoning behind it is gone.
Spec-driven development fills this gap. It gives coding agents structured intent: requirements, edge cases, and expected behavior, formalized as Markdown files in the Git repository. With specs anchored next to the code, the coordination patterns teams already use apply automatically. Branch them, review them, merge them.
This works whether features build on each other or develop in parallel. When an engineer extends a colleague’s recently merged work, their agent finds the relevant specs and understands the intent behind the code. When two engineers work on separate features at the same time, each agent has the full spec library as context, and both sets of specs merge through the normal PR process.
I built speq-skill to enable this: an iterative, shared workflow for spec-driven development that supports parallel feature work, both within a team and as a solo developer. Here’s how the workflow looks in practice.
The workflow#
Consider this scenario. Tim is adding a payment retry system. Hannah is building an invoice export feature. Both work on separate feature branches. The diagram below shows the full lifecycle.
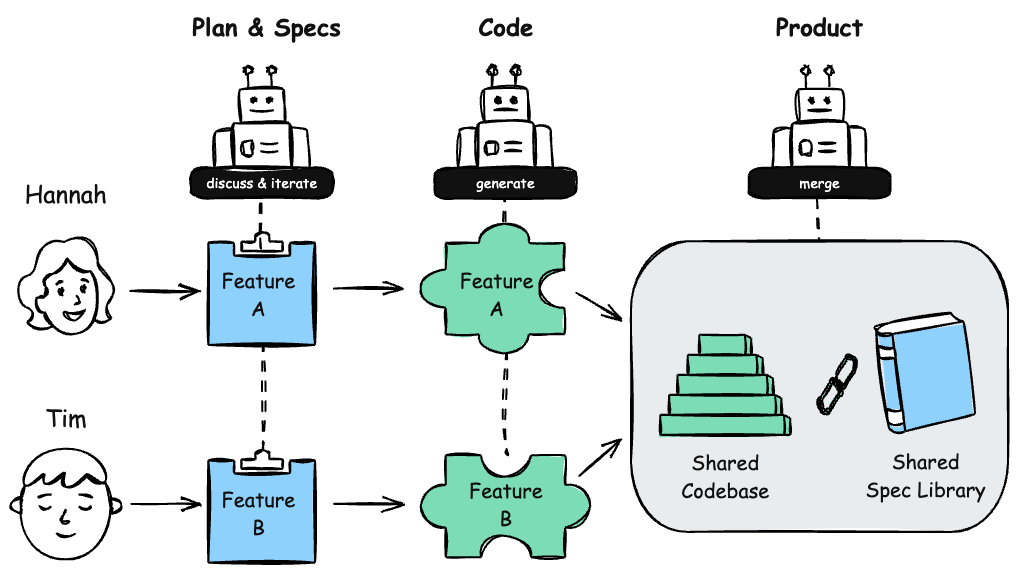
Tim plans his feature. He creates a branch and plans with his agent. The agent searches the existing spec library on main, finds relevant specs, and uses them as context. It conducts a clarifying interview: What exactly should happen when a payment fails? How many retries? What’s the backoff strategy? Together they produce spec deltas: markdown files describing the new behavior in BDD-style scenarios. The spec deltas land in specs/_plans/ on Tim’s branch, the staging area.
Tim’s agent implements. It reads the spec deltas and builds the feature, writes integration tests that validate each scenario, runs them, and verifies everything works. The staging area stays active throughout, pushed to the branch alongside the code. Nothing touches main.
Hannah does the same on her branch. She plans her invoice export, produces her own spec deltas, and implements independently. Her agent loads the spec library from main plus her own staging area. The two branches develop in parallel.
Tim records and opens a PR. When implementation is complete and verified, Tim records his specs. This moves the deltas from the staging area into the permanent spec library, still on his feature branch. He opens a pull request that includes code, tests, and the recorded specs. The reviewer sees both what Tim built and what he intended. Humans evaluate architecture and design. The AI checks correctness: does the implementation match the specs? Are the scenarios covered by tests? The spec and the code are reviewable together, in one place.
The PR merges. main now includes Tim’s feature, his tests, and his specs.
Hannah rebases. She pulls in Tim’s changes. If there are conflicts in the specs, they’re handled the same way as code conflicts. Her coding agent can resolve straightforward ones and ask clarifying questions when the intent is ambiguous. After rebasing, Hannah’s agent has access to Tim’s merged specs when it searches the library.
The cycle repeats with every feature.
The spec library grows with the team#
Every time a feature is merged, its requirements and scenarios update the permanent spec library on main. The next time any engineer plans a feature, their agent searches this library and loads the relevant requirements and scenarios into its context window.
Tim’s agent now knows about Hannah’s invoice export, even if Tim never looked at her code. If Hannah’s export spec says “the system SHALL exclude archived invoices older than 90 days,” Tim’s agent picks that up when planning a reporting feature that aggregates invoice data. Without that spec, Tim’s agent might have included archived invoices, creating an inconsistency nobody catches until a customer files a bug.
The shared spec library acts as a shared memory bank both for humans and coding agents.
Solo devs: git worktrees#
The same workflow works for a solo developer building multiple features in parallel. Git worktrees give you multiple checked-out branches simultaneously, each with its own staging area and agent session. Same discipline, same coordination through the spec library on main.
Get started#
speq-skill is open source and free to use. Get started here: github.com/marconae/speq-skill.
If you want to dig deeper into the ideas behind this workflow, start with Spec-driven development: an introduction and Writing specs for AI coding agents. For the tool that puts it all together: Introducing speq-skill.